
The problem.
CLIP, standing for Campus Life Integration Platform, is NOVA University’s e-learning and academic management platform where most class files, notes, and grades are uploaded. It’s old, it barely functions, and it’s super slow.
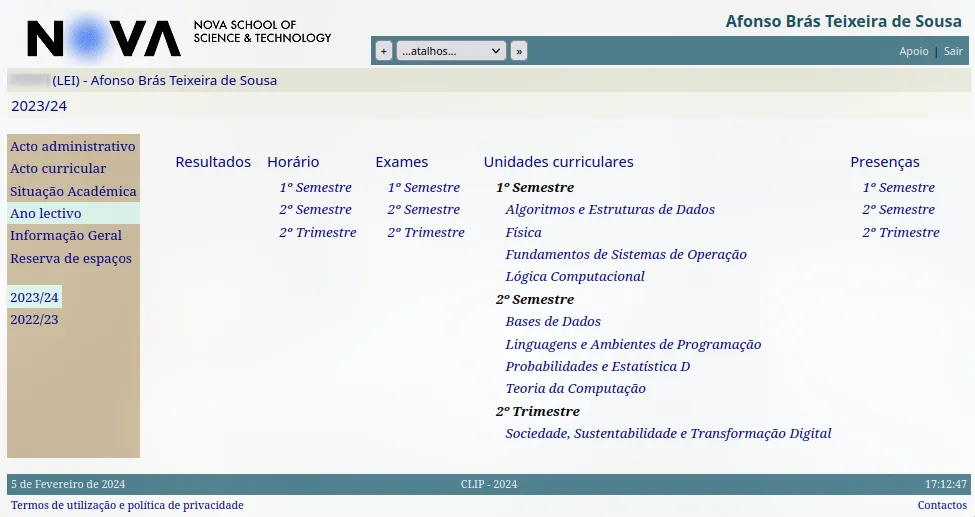
Checking if your class professor uploaded a new file and downloading it requires you to go to four or five different pages after logging in. In summary, it’s not very good.
my solution.
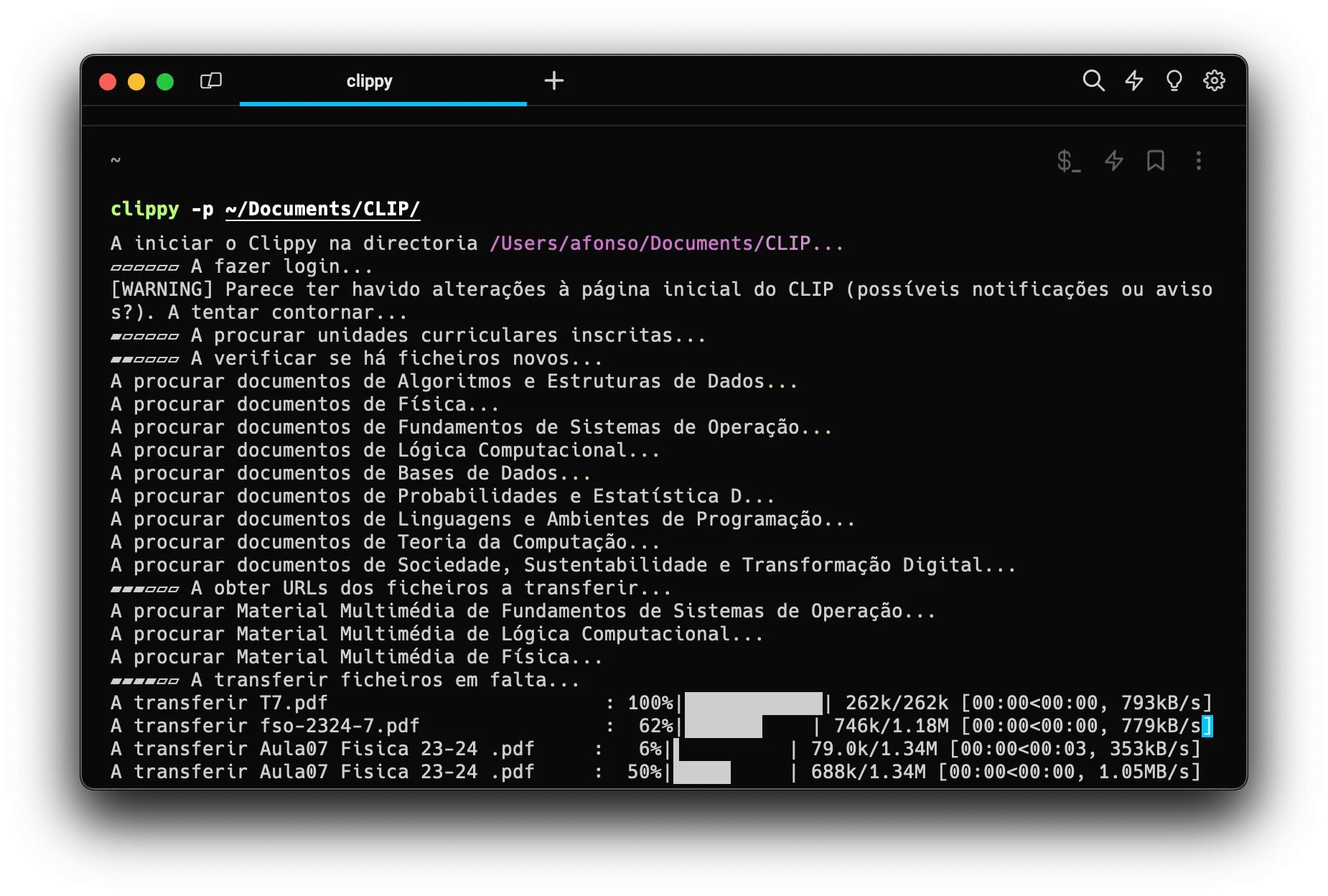
While studying Python and looking into data scraping libraries, specifically Pandas, i wanted to make a personal project that would be useful to me and others. From there, the idea to build a script that would browse CLIP for me and download any new files seemed like a logical next step.
i wanted to make it easier to install and use so i found the excellent Click package that sped up the creation of a CLI interface while Poetry made it easy to publish without dependency management hell.
After an initial successful build, i looked into optimizing it and making it cross-platform. UPX and PyInstaller allowed me to convert it into a Windows EXE file that can be run without installing Python. i eventually removed the Pandas dependency for a simpler Regex implementation which made the app size 63% smaller.
The result.
Clippy currently officially supports all major operating systems on PC (Windows, MacOS and Linux) and also Android devices.
It’s available now! Installing instructions are on the Github repository. i have refrained from publishing it to PyPI as i think this is a project that still is mostly useful only to NOVA students and teachers, not the wider web.